
Amazon Athenaをさわってみた
-
こんにちわ。JMAS 岸本です。
お待たせしております。
Amazon Rekognition(画像認識)をさわってみた その2の続きです!上記の記事で、
画像をS3に置いただけでCSVファイルが作成されるまでやりました。しかし、このままでは、
画像ファイルの数だけS3にCSVファイルが作成されてしまうので、
データの閲覧や抽出に手間がかかります。EMRやRedshiftなどの選択肢もありますが、
今回は予告通り、Amazon Athenaを使ってデータの抽出をしたいと思います。Amazon Athenaとは
S3内のデータを指定してスキーマを定義すると、SQLのクエリを投げる事で、
ファイルが分割されていようと、横断的にデータの抽出ができます。
加えて、コンピューティングリソースを用意する必要がないのも特徴です。re:Invent2016のAthena発表時は、
マネジメントコンソールとJDBCにのみ対応していましたが、
5月の中旬に、API/CLIからのクエリ実行にも対応しています。→発表記事※詳しくは→Amazon Athena
今回は、マネジメントコンソールでの操作を実施してみたいと思います。
データベースとテーブルの定義
マネジメントコンソールにログイン後、Athenaのページへ移動します。
Step1
初めての利用であれば、チュートリアルが始まるのですが、
このアカウントでは初めての利用では無いので、
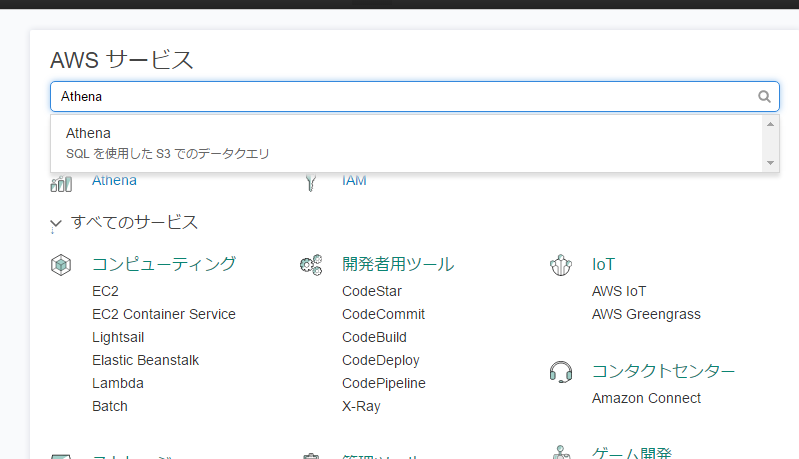
“Catalog Manager”を選択し、”+ Add table”をクリックして下さい。
その後、画像の様に入力し、次へ
Step2
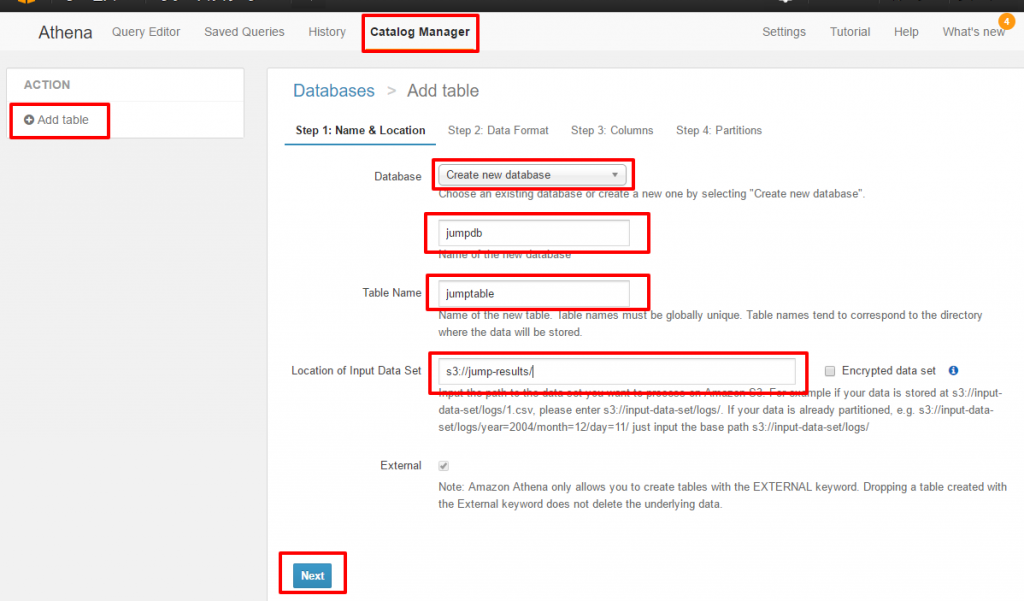
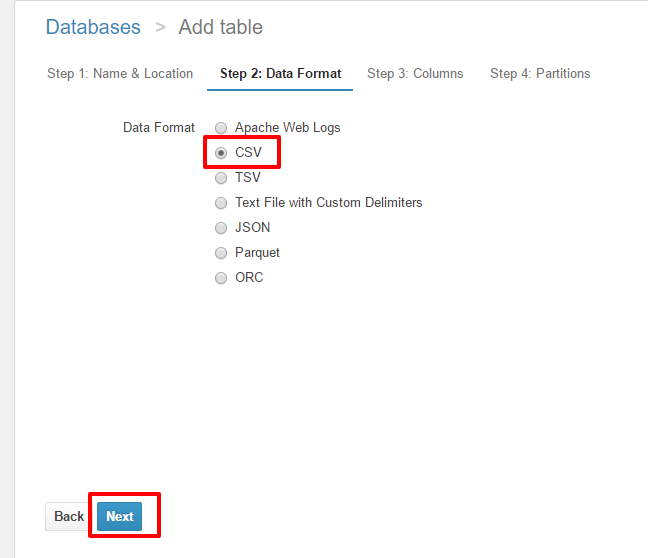
S3上のデータのデータのフォーマットを定義します。
今回はLambdaがRekognitionの結果をCSV形式でS3へ保存しているので、
“CSV”を選択し、次へ
Step3
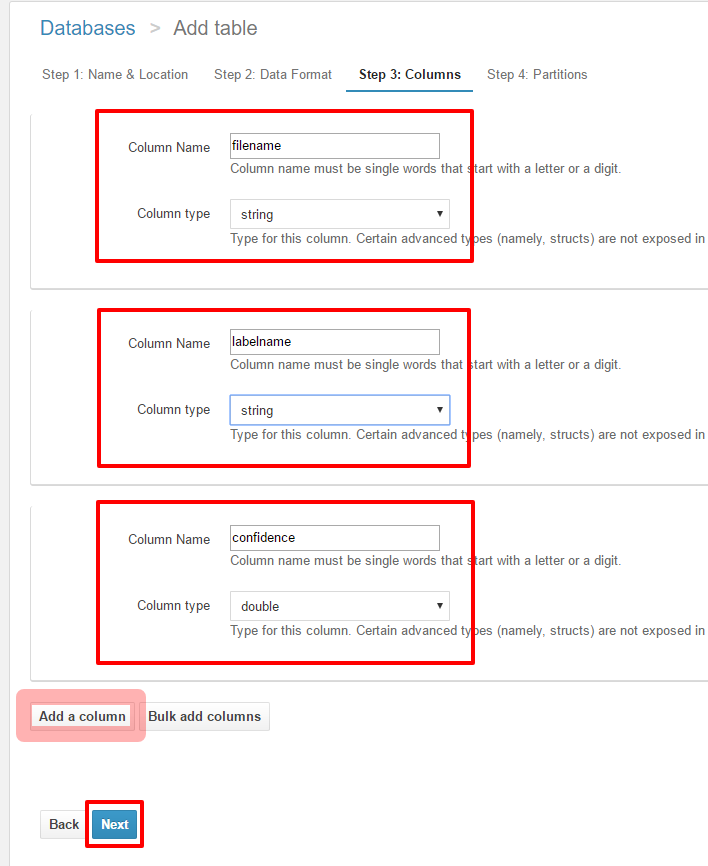
カラム名/データ型を定義します。
Lambdaが出力するCSVの各列の要素を確認しながら定義していきます。
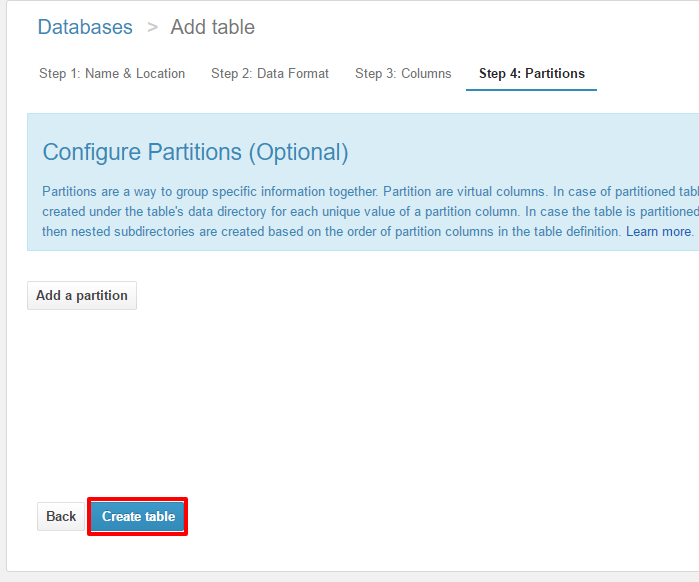
Step4
パーティションについては、今回は使用しませんので、
そのまま”Create table”を選択
※ここでパーティションを定義すると、
データをスキャンする対象ファイルを絞り込む事が出来るので、
コスト削減・パフォーマンス向上を図ることができます。
Hiveフォーマット等、決まった形式でS3にファイルが保存されている場合は
利用するべきですし、ファイルを保存する処理も意識した方が良いと思います。
画面遷移後、”Query successful.”の文字と、
左ペインに作成したデータベースとテーブルが表示されています。
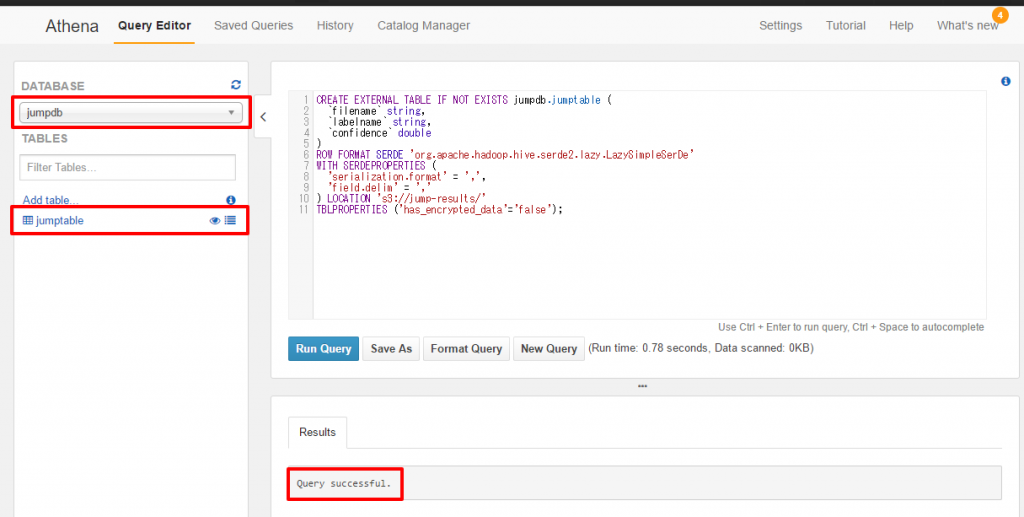
ここからは、中央のQuery Editorにクエリを記載し、データを抽出してみます。
【補足】AthenaのSQLについて
Amazon Athena では、
標準SQLをフルサポートしたPrestoを基盤テクノロジーとしており、
SQL互換言語があるので、そこまで難しくありません。
※Prestoについては、ここでは言及しません。全件取得
今回の為に、社内のメンバーに200枚ほど画像を追加していただきました。
横断的にファイルの中身が見えているかを確認する為、
まずは全件取得してみましょう。下記SQL文をQuery Editerに入力し、”Run Query”をクリック
SELECT * FROM jumptable;
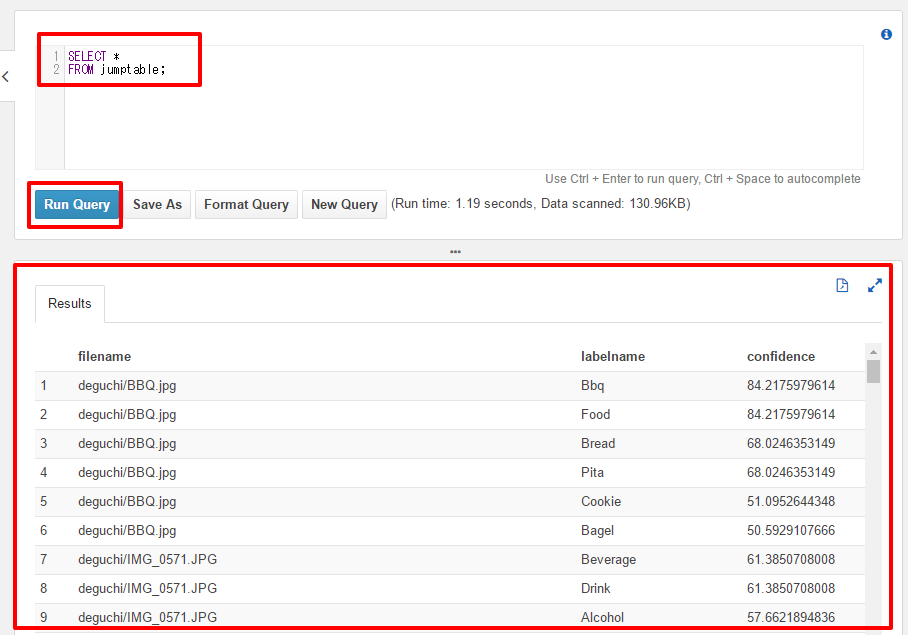
ResultsがQuery Editerの下部にクエリの結果が表示され、
異なるfilenameが混ざっている事がわかります。レコード件数取得
次は、レコード件数の取得です。
下記SQL文をQuery Editerに入力し、”Run Query”をクリック
SELECT count(*) FROM jumptable;
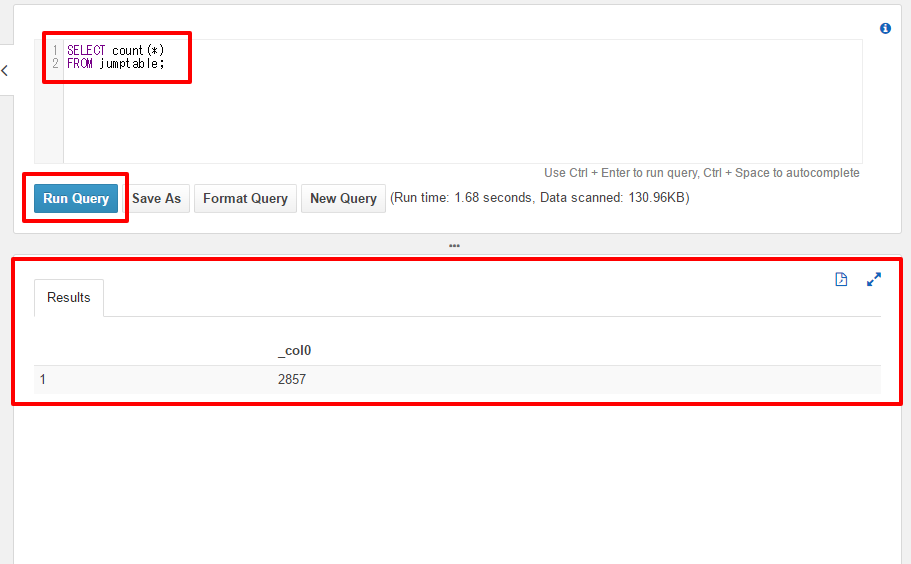
全てのCSVファイルの合計で、2857レコードのデータがある事がわかります。
信頼度が95%以上のLabelの数を取得
ちょっとだけ条件を付けて、データを抽出してみたいと思います。
Rekognitionによる解析の結果、
95%以上の信頼度が付いているLabelのそれぞれの出現回数を抽出してみます。下記SQL文をQuery Editerに入力し、”Run Query”をクリック
SELECT labelname , Count(labelname) FROM jumptable WHERE confidence > 95 GROUP BY labelname;
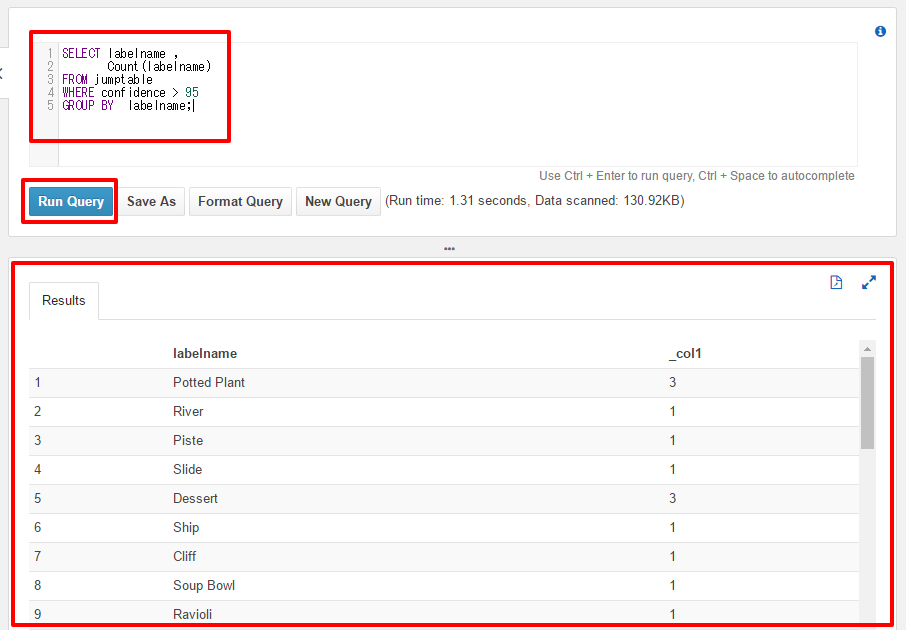
label毎のカウントが抽出出来ました。
下記、赤枠のアイコンをクリックすれば、
結果のデータをCSVとしてダウンロード出来ます。
何が多く写っている?
ダウンロードしたCSVを見てみます。
People,110 Human,110 Person,110 Food,7 Furniture,7 Plant,6 Outdoors,5 Chair,5 Flower,4 Cherry Blossom,4 Blossom,4 Potted Plant,3 Dessert,3 Architecture,3 Dinosaur,3 Lantern,3 Flora,3 Water,3 ・ ・ ・
People,Human,Personと
人が写っている写真が多いようですね。
いろんなものが写っている写真を用意すれば、
数値としてもわかりやすかったのですが…感想
今回は、同一の値が多いデータを対象としたので、
少しわかりにくかった部分がありました。
しかし、アクセスログ・センサーデータ・POS情報など、
大量のデータを横断的に見ることが出来るのは、非常に魅力的です。また、APIやJDBCを使って、Athenaを動かす事で
・Lambdaと連携した、定期的なレポート出力
・BI等、他システムとの統合
も可能なので、使う場面は多いと思います。株式会社jena様と弊社で共同開発している“Beacapp”も
大量のデータを取り扱っているので、
Athenaを使う事でさらなる進化を遂げるかも知れません!最後に
本ブログも、記事数は少ないものの、たくさんの人に閲覧いただき、
たくさんのフィードバックをいただいております。
本当にありがとうございます。より魅力的なブログにする為、これからも頑張って参りますので、
よろしくお願いいたします!人気記事