AWS移行プロセスシリーズ第3回:運用&最適化フェーズ

みなさま こんにちは、JMASの島田です。
今回のコラムは、AWS移行プロセスシリーズ の最終回「運用&最適化フェーズ」についてお話します。
▼AWS移行シリーズ
第1回:移行準備フェーズ
第2回:移行フェーズ
第3回:運用&最適化フェーズ(本コラム)
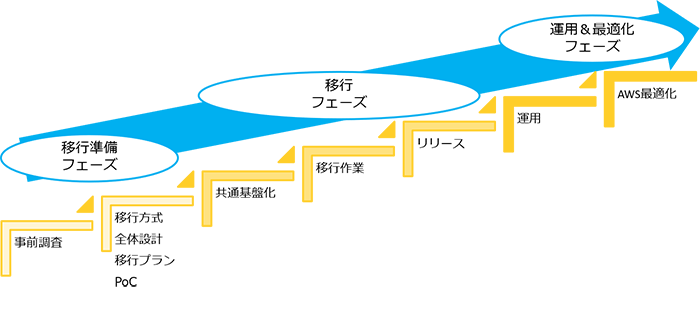
第1回:移行準備フェーズでは、移行の準備に必要な以下の4つについてご紹介いたしました。
1)事前調査
2)移行方式検討
3)全体設計
4)移行プラン
第2回:移行フェーズでは、移行プランに対する実際の移行作業としてポイントとなる、以下の2つについてご紹介いたしました。
1)共通基盤を構築する方法
共通基盤について
アカウント分割例
2)2つの移行パターンのご紹介
サーバをそのまま移行する「Re-Hostパターン」
リビルドして移行する「Re-Platformパターン」
移行のプロセス、方法についてご理解いただけましたでしょうか?
クラウドでシステムを早く、安心、安全に運用していくうえで、「第2回移行フェーズの1)共通基盤を構築する方法」で紹介した、共通基盤機能は、必要な項目となります。まだ確認いただけない方は、ぜひご覧ください。
第3回 運用&最適化フェーズ
システムを長く運用する際にポイントとなることは、コストです。
単純にクラウドへ移行して終わりではなく、クラウドの良さを最大限活用することで、コストメリットを受けることができます。発生しているコストを把握して、次の投資へつなげることは非常に重要な考え方になります。
移行後に発生するコストの内容を把握して、クラウドの最適化に向けた方法を考えていきましょう!!
1)クラウド移行後の運用管理コスト
2)クラウド利用料に対するコスト
・Auto Scale(オート スケール)の活用
・マネージドサービスの活用
3)運用にはクラウドの知見が必要
4)AWSマネージドサービスを活用した運用プラットフォーム
クラウド移行後の運用管理コスト
- CPU、メモリなどのリソース情報の管理・監視
- リソース追加
- セキュリティホールを発生させないためのOS、ミドルウェアのパッチ管理・監視
- 万一に備えたシステムバックアップおよびその世代管理・監視
クラウド利用料に対するコスト
- Auto Scale(オート スケール)の活用
- マネージドサービスの活用
これらのコスト削減をするためには、リソース管理を行い、負荷によって自動でリソースを調整するAuto Scaleの利用が有効です。
Auto Scaleを活用すればスムーズなインフラの増強が可能で、予測できない急なアクセス増にも柔軟に対応することができます。自動的にインスタンスの追加・削除等をしてくれるので、管理作業、クラウド利用料の最適化が可能になります。
![]() 引用:AWSのクラウドが選ばれる10の理由 <理由3 サイジングからの解放>
引用:AWSのクラウドが選ばれる10の理由 <理由3 サイジングからの解放>
ただし、自動でサーバ台数が増減ということはシステムがステートレスである必要がありますね。そのため、ステートレスなアプリケーションに改修する必要があります。ステートレスにするために機能分割を行い、機能ごとにサーバを構築した場合は、構築に時間もかかりますし、AWS利用料、運用コストも増加してしまいメリットとして感じられなくなってしまいます。そのため、短期間でかつ、低コストで完了させるために、サービスを細かく切り分け、クラウド事業者が提供する運用管理なども一体として提供してくれるマネージドサービスを利用することを検討してください。
マネージドサービスの活用によりクラウドの利用者は、システム運用の負荷を軽減することができます。そのためマネージドサービスの利用が推奨されています。まずは、クラウド移行を実施 => 疎結合化 => 個々コンポーネントのマネージドサービスへ切り替えといった順に検討することが、正しい最適化へのワークロードだと考えております。
- 単純なクラウド移行 => 疎結合化 => 個々のコンポーネントをマネージドサービスへ切り替える検討
- 各コンポーネントのコミュニケーション部分(アプリケーションとデータベースの通信等)を置き換える「疎結合化」のみ実施
- 次段階で、分離したキャッシュ、データベースをマネージド化(具体例:Amazon ElastiCache、Amazon Aurora)など
ただし、2については、時間もコストがかかるため、3へそのまま移行することを推奨いたします。
クラウドマネージドサービスは、セキュリティも強固で、運用機能もあり、多くのメリットがありますが、いきなり使うことに障壁を感じる方は、お問い合わせください。マネージドサービスの利用経験豊富な弊社エンジニアがご支援させて頂きます!!
データベース、キャッシュ、コンタクトセンター、AI、MLなど多数のマネージドサービスが存在しており、その数は日々増加しております。
だたし、マネージドサービスを利用するうえで、もちろん課題もあります。利用者自身が管理できる範囲が減り、復旧はクラウドベンダに頼らざるを得ないこともあります。システム障害を起こさない事を前提ではなく、システム障害は起こるものとして失敗時のリトライ方法など異常系の処理をどうするかをきちんと考える必要があります。
![]() 引用:AWSのクラウドが選ばれる10の理由 <理由5最先端の技術をいつでも利用可能>
引用:AWSのクラウドが選ばれる10の理由 <理由5最先端の技術をいつでも利用可能>
運用にはクラウドの知見が必要
- メンテナンス情報の管理
- 高い自由度を考慮したクラウドサービスに対する権限
- 操作ログの管理
- 利用料金の管理 など
AWSでは、正常系、異常系の結果もシステムのパフォーマンスに関するデータはメトリクスとして表現されているため、この各メトリクスに出力される内容をきちんと把握し、監視サービスと組み合わせるなどして、適切なアクションを行う必要があります。
異常系のメトリクスを見落としてしまうと、実はマネージドサービスが期待通りに動いてなかったとかを、後々知ることになるので、注意が必要です。
また、AutoScaleの動きを例にとっても、サーバが停止したタイミングでディスクがなくなります(残すこともできますが、、)。
「あれ?ディスクがない、、、どうやってログ見るの?」といったことが発生しないように、アーキテクトを正しく理解して、運用設計を行う必要があります。手順書を作成し、対応することも可能ですが、ベースとなる動きの理解のためにも、運用者はクラウドの知見が必須だと考えてます。
AWSマネージドサービスを活用した運用プラットフォーム
また、クラウド活用は、障害が発生する前提で準備をし、オートマチックで運用できる仕組み作りが重要だと考えております。そのためにはクラウドを最適に活用することが必要になってきます。
コンサルティングから構築、運用、およびアプリケーション開発までワンストップでの対応が必要であると考えており、JMASはお客様にクラウドを最適に活用いただける、『JMAS Cloud Optimum Service(略称 J-COS)』を提供しております。
AWSのマネージドサービスを活用し、最適な運用共通基盤をスピーディかつ安価に提供する『運用共通プラットフォームサービス』もラインナップしており、企業システムとして安全性を確保しながら、よりスムーズなシステム運用が可能になります。
簡単に利用開始できるクラウドを使って、内製化の動きが今後はさらに進むと考えております。しかし、正しく活用するためには、失敗も含めた多くの経験が必要です。
弊社では自社製品、R&D活動、およびDX促進支援として、多数のマネージドサービスを利用しており、実績も多数あります。
「AWSへ移行しただけで、これからどうして良いかわからないんだよね?」
という方は、ぜひお気軽にお問い合わせください。

![]()
クラウドは日々進化し便利になっており、我々の生活を変えてくれます。
今回のコラムがみなさまのAWS活用の助力となれば幸いです。